The-Art-of-Problem-Solving-in-Software-Engineering_How-to-Make-MySQL-Better
4.4 Operating system
An operating system (OS) is system software that manages computer hardware and software resources and provides common services for computer programs [45].
MySQL is primarily deployed on the Linux operating system. To maintain focus, the discussions here are based on scenarios within the Linux operating system environment. This includes CPU scheduling, process and thread models, staged models, memory allocation, and system calls, all of which are closely related to MySQL performance.
4.4.1 CPU Scheduling
The job of allocating CPU time to different tasks within an operating system is known as CPU scheduling. The organizational structure of Linux CPUs is illustrated in the figure below [53].
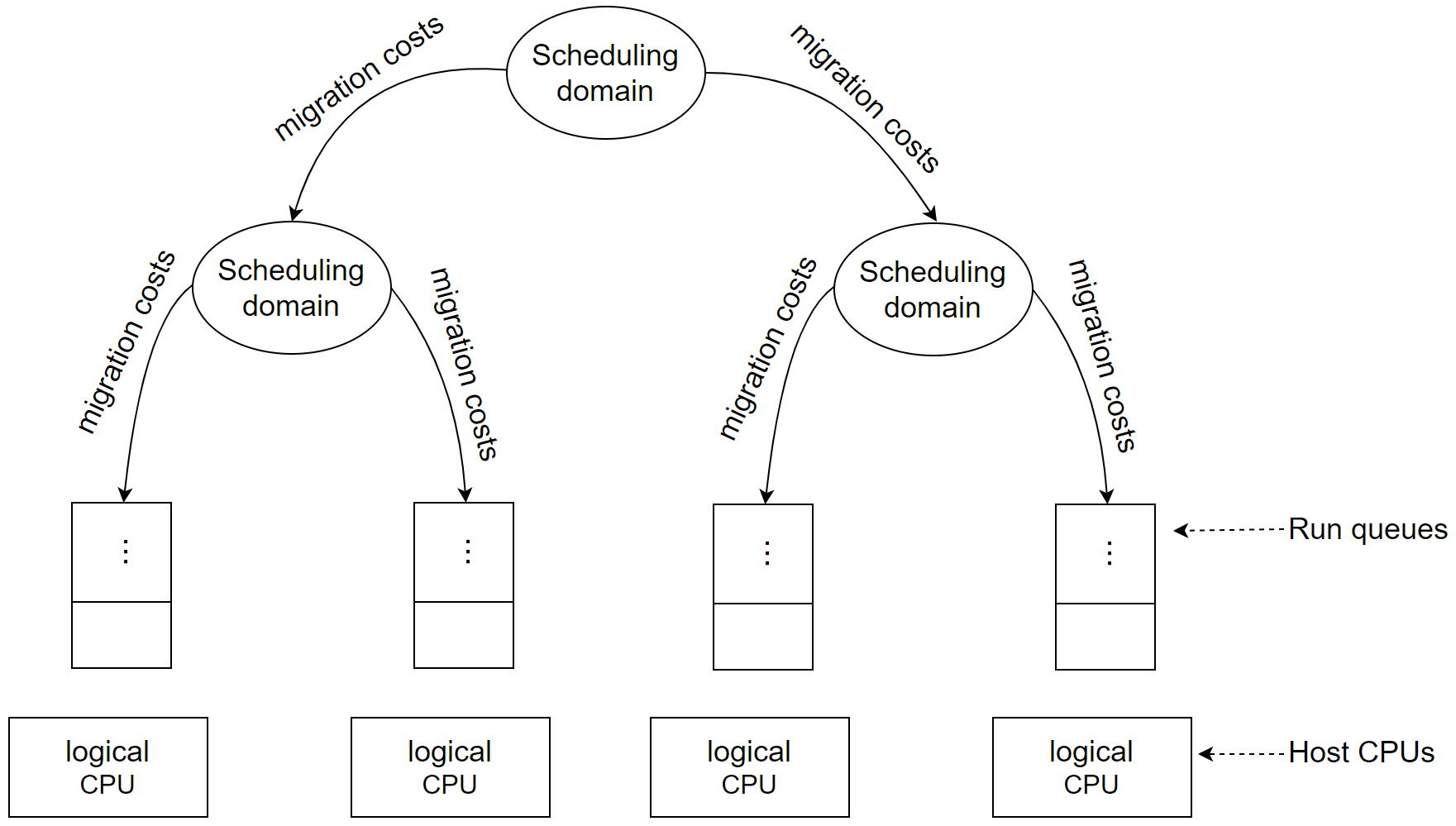
Figure 4-15. Linux CPU scheduling.
Based on the hardware layout of physical cores, the Linux scheduler maintains hierarchically ordered scheduling domains. Basic scheduling domains consist of processes running on physically adjacent cores, such as those on the same chip. Higher-level scheduling domains group these basic domains, such as chips on the same motherboard.
The Linux scheduler operates as a multi-queue scheduler, meaning that each logical host CPU has its own run queue of processes waiting to be executed. Each virtual CPU is queued in one of these run queues. Moving a virtual CPU from one run queue to another is referred to as CPU migration. The scheduler may decide to migrate a virtual CPU when the estimated wait time is too long, the current run queue is full, or another run queue needs to be filled.
Migrating a virtual CPU within the same scheduling domain incurs less cost compared to moving it to a different domain due to the proximity of caches between cores. The Linux scheduler uses detailed information about migration costs between different scheduling domains or CPUs to determine if a migration is beneficial.
Understanding CPU scheduling details is crucial for diagnosing MySQL performance problems. A key question is whether Linux’s scheduling mechanisms can effectively manage thousands of concurrent threads in MySQL. Since MySQL operates on a thread-based model, it’s important to assess how the Linux scheduler handles such a high volume of threads. Does it simply allocate CPU time evenly among them?
Consider a scenario where there are N user threads and C CPU cores, with each core supporting dual hyper-threading. Ideally, without considering context switch overhead, each user thread should receive the following CPU execution time per second.
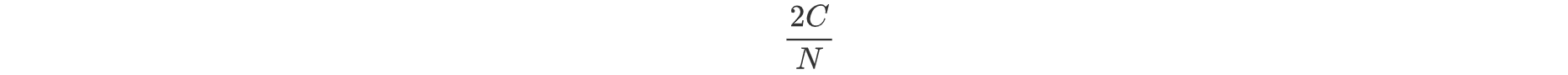
As N increases, the average CPU allocation per thread decreases. For example, if N=100000 and C=3, each thread would only receive about 60 microseconds of CPU time per second. Given that context switches typically incur costs in the tens of microseconds range, a significant portion of CPU time would be lost to context switching, thereby reducing overall CPU efficiency.
As the number of user threads increases, the Linux scheduler struggles to manage CPU time effectively, resulting in inefficiencies and performance degradation due to frequent context switches. To address this, the system enforces a minimum execution granularity, ensuring that each process runs for at least 100 microseconds before being preempted. This approach minimizes the inefficiencies of short scheduling intervals. The Completely Fair Scheduler (CFS) uses this minimum granularity to prevent excessive switching costs as the number of runnable processes grows.
At the same time, increasing the number of CPU cores ensures that each user thread receives sufficient execution time. Coupled with maintaining a minimum execution granularity, the cost of context switching can be significantly mitigated.
Next, let’s examine the cost of thread blocking. The disadvantage of blocking is the cost of context switching—typically 12-20 microseconds—which must be performed twice per lock handoff (once to sleep, and again to wake) [3]. In general, under the condition of maintaining minimum execution times, the cost of context switching compared to current mainstream hardware environments is already quite minimal. Therefore, employing blocking methods has practical value.
Further examining how Linux CPU schedules threads for running programs, specifics can be seen in the figure below:
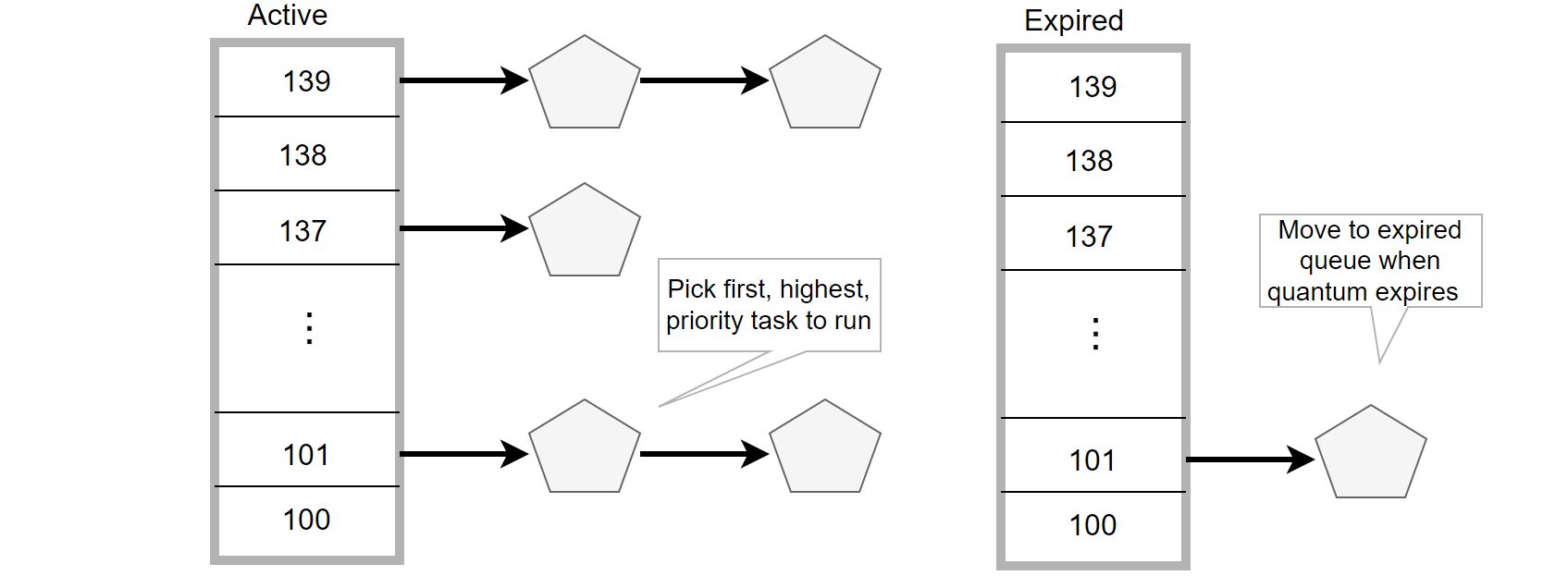
Figure 4-16. How Linux CPU schedules threads for running programs.
The smaller the number, the higher the priority level. The scheduler prioritizes threads with higher priority levels, and after a thread’s time slice expires, it is placed in the “expired” queue.
MySQL internal threads can be in different states such as running, waiting for I/O, or waiting for locks. Threads waiting for disk I/O are placed into the corresponding disk wait queue and are not scheduled by the Linux scheduler into the active or expired queues.
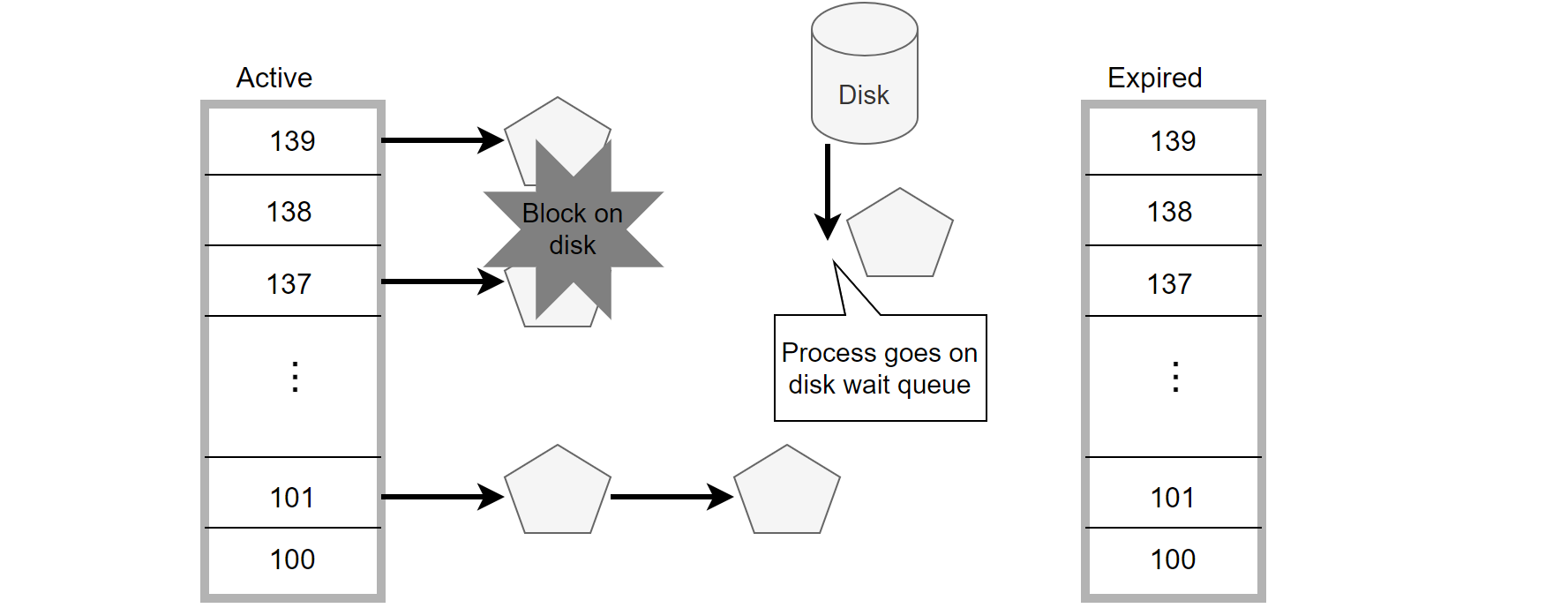
Figure 4-17. Linux CPU scheduling of threads waiting for I/O.
This means that these threads waiting for I/O have little impact on other active threads. In MySQL, transaction lock waits function similarly to I/O waits—threads voluntarily block themselves and wait to be activated, which is generally manageable in cases where conflicts are not severe.
It is worth mentioning that it is advisable to avoid having a large number of threads waiting for the same global latch or lock, as this can lead to frequent context switches. In NUMA environments, it can also cause frequent cache migrations, thereby affecting MySQL’s scalability.
With the increasing number of CPU cores and larger memory sizes available today, the impact of thread creation costs on MySQL has become smaller. Except for special scenarios such as short connection applications, MySQL can handle a large number of threads given sufficient memory. The key is to limit the number of active threads running concurrently. In theory, MySQL can support thousands of concurrent threads.
Using principles of CPU scheduling, MySQL implements transaction throttling mechanisms, such as limiting the number of threads entering the InnoDB transaction system. This ensures that the concurrency of transactions remains manageable. Too many threads entering InnoDB can lead to latch contention, significantly reducing efficiency.
The following figure illustrates the use of transaction throttling mechanisms to limit a maximum of 512 threads entering the InnoDB storage engine, depicting MySQL’s single-instance throughput from 50 to 10,000 concurrency.
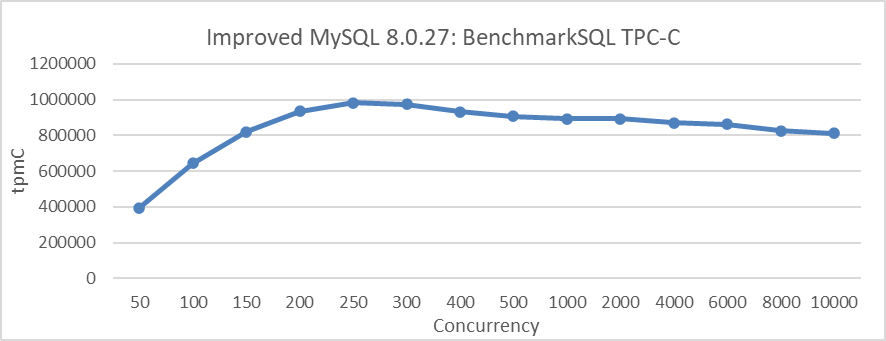
Figure 4-18. Maximum TPC-C throughput in BenchmarkSQL with transaction throttling mechanisms.
As illustrated in the figure, TPC-C throughput exceeds 800,000 tpmC even at 10,000 concurrency, showing only a slight decrease from the peak value.
4.4.2 Process Model
In Linux, processes and threads are fundamental to multitasking and parallel execution. A process is an independent execution unit with its own memory space, while a thread is a smaller execution unit within a process, sharing its memory space.
Key differences include:
- Memory Consumption: Processes require separate memory space, making them more memory-intensive compared to threads, which share the memory of their parent process. A process typically consumes around 10 megabytes, whereas a thread uses about 1 megabyte.
- Concurrency Handling: Given the same amount of memory, systems can support significantly more threads than processes. This makes threads more suitable for applications requiring high concurrency.
When building a concurrent database system, memory efficiency is critical. MySQL’s use of a thread-based model offers an advantage over traditional PostgreSQL’s process-based model, particularly in high concurrency scenarios. While PostgreSQL’s model can lead to higher memory consumption, MySQL’s threading model is more efficient in handling large numbers of concurrent connections.
Additionally, although Nginx uses a multi-process model, it achieves scalability through asynchronous programming techniques.
4.4.3 Thread Model
For MySQL, the thread-based model is advantageous over the process model due to its theoretical support for tens of thousands of concurrent threads. However, the paper “A Case for Staged Database Systems” highlights some shortcomings of this model [21].
Challenges of the Thread-Based Model:
- Cache Performance: The thread-based execution model often results in poor cache performance with multiple clients.
- Complexity: The monolithic design of modern DBMS software leads to complex, hard-to-maintain systems.
Pitfalls of Thread-Based Concurrency:
- Thread Management: There is no optimal number of preallocated worker threads for varying workloads. Too many threads can waste resources, while too few restrict concurrency.
- Context Switching: Context switches during operations can evict a large working set from the cache, causing delays when the thread resumes.
- Cache Utilization: Round-robin scheduling does not consider the benefit of shared cache contents, leading to inefficiencies.
Despite ongoing improvements in operating systems, the thread model continues to face significant challenges in optimization.
In MySQL, a significant problem occurs when a large number of threads enter the InnoDB transaction system. This increases latch contention and extends the MVCC ReadView global active transaction list, causing frequent cache migrations. This problem is especially pronounced in ultra-high concurrency scenarios. For example, the figure below shows how Group Replication throughput varies with concurrency in a network environment with 10ms latency.
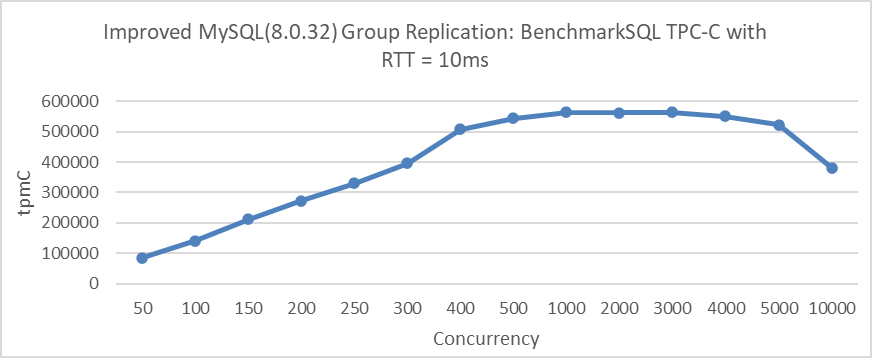
Figure 4-19. Maximum thread scalability of Group Replication under 10ms network latency.
At 5000 concurrency, throughput remains relatively stable. However, beyond this point, throughput declines sharply. In extremely high concurrency scenarios, severe latch conflicts and frequent cache migrations significantly reduce MySQL’s efficiency.
4.4.4 Staged Model
The staged model is a specialized type of thread model that minimizes some of the drawbacks associated with handling numerous concurrent threads. This model involves breaking the database system into distinct modules, each encapsulated into self-contained stages interconnected through queues. By addressing both hardware and software challenges, the staged model provides effective solutions to the limitations of traditional DBMS designs [21].
Benefits of the Staged Model
- Targeted Thread Allocation: Each stage allocates worker threads based on its specific functionality and I/O frequency, rather than the number of concurrent clients. This approach allows for more precise thread management tailored to the needs of different database tasks, compared to a generic thread pool size.
- Voluntary Thread Yielding: Instead of preempting a thread arbitrarily, a stage thread voluntarily yields the CPU at the end of its stage code execution. This reduces cache eviction during the shrinking phase of the working set, minimizing the time needed to restore it. This technique can also be adapted to existing database architectures.
- Exploiting Stage Affinity: The thread scheduler focuses on tasks within the same stage, which helps to exploit processor cache affinity. The initial task brings common data structures and code into higher cache levels, reducing cache misses for subsequent tasks.
- CPU Binding Efficiency: The singular nature of thread operations in the staged model allows for improved efficiency through CPU binding, which is especially effective in NUMA environments.
The staged model is extensively used in MySQL for tasks such as secondary replay, Group Replication, and improvements to the Redo log in MySQL 8.0. However, it is not well-suited for handling user requests due to increased response times caused by various queues. MySQL primary servers prioritize low latency and high throughput for user-facing operations, while tasks like secondary replay, which do not interact directly with users, can afford higher latency in exchange for high throughput.
The figure below illustrates the processing flow of Group Replication. In this design, Group Replication is divided into multiple subprocesses connected through queues. This staged approach offers several benefits, including:
- High Efficiency: By breaking down tasks into discrete stages, Group Replication can process tasks more effectively.
- Cache-Friendly Access: The design minimizes cache misses by ensuring that related tasks are executed in sequence.
- Pipelined Processing: Tasks are handled in a pipelined manner, allowing for improved throughput
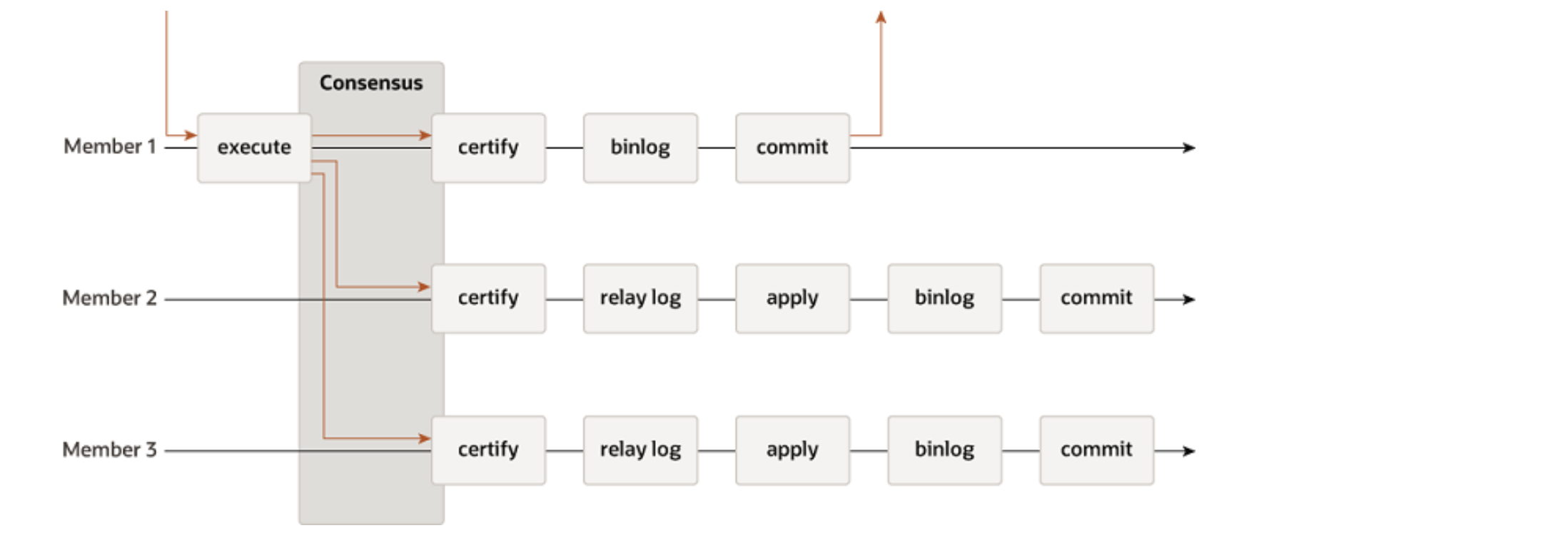
Figure 4-20. MySQL Group Replication protocol.
In the staged model, using a single thread can become a bottleneck when processing large amounts of data. For instance, in the apply replay process shown in the figure, the thread is responsible for both CPU-intensive tasks, such as reading and decoding the relay log, and for scheduling and coordination. This can significantly hinder the performance of MySQL secondary replay, limiting its ability to process data efficiently and quickly.
4.4.5 Memory Allocation
The Linux memory management subsystem oversees virtual memory, demand paging, and memory allocation for both kernel structures and user programs. Memory hot-spots often arise from improper data initialization [4], especially under the default first-touch policy, which can lead to uneven memory distribution across NUMA nodes. To mitigate this, initialize data in the computation-partition where it will be used.
Modern CPUs generate high memory request rates that can overwhelm the interconnect or memory controller. NUMA systems, with their numerous hardware threads, face scalability problems due to concurrent memory allocation requests. Solutions include overriding the memory allocator, defining thread placement and affinity schemes, and adjusting OS configurations. Efficient memory allocators are particularly beneficial in NUMA systems where performance penalties from inefficient memory or cache use can be significant.
Linux prioritizes local node allocation and minimizes thread migrations across nodes using scheduling domains. This reduces inter-domain migrations but may affect load balance and performance. To optimize memory usage:
- Identify memory-intensive threads.
- Distribute them across memory domains.
- Migrate memory with threads.
Understanding these memory management principles is crucial for diagnosing and solving MySQL performance problems. Linux aims to reduce process interference by minimizing CPU switches and cache migrations across NUMA nodes.
The figure below illustrates a comparative experiment. The deep blue curve shows the total throughput of running four MySQL instances on a NUMA system without node binding. In contrast, the deep red curve represents the total throughput when each MySQL instance is bound to different NUMA nodes. This latter setup reflects the ideal throughput, as it minimizes CPU scheduling interference between MySQL instances.
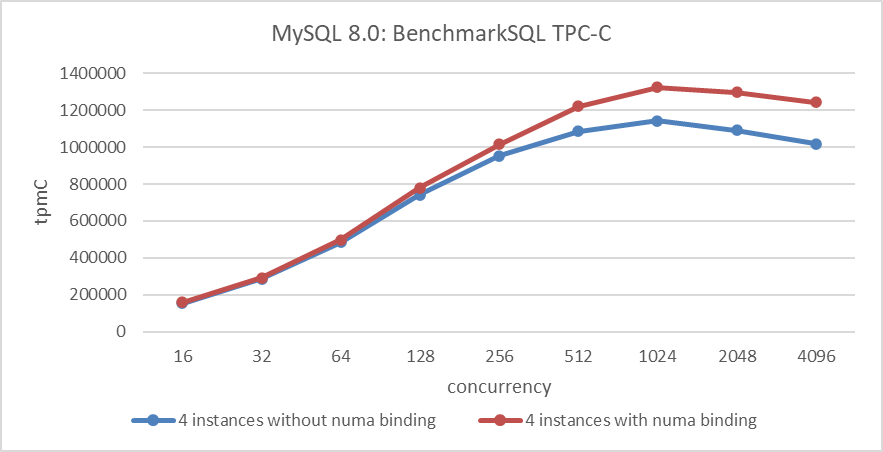
Figure 4-21. Comparing ideal NUMA scheduling with actual Linux scheduling of multiple instances.
Based on the figure, it’s evident that while the operating system strives to approach the ideal throughput under low concurrency, the gap widens as concurrency increases. This widening gap occurs because memory scheduling becomes more complex with a higher number of threads.
For MySQL applications, effectively utilizing NUMA-based memory allocation is crucial. Test results indicate that for TPC-C type workloads, disabling NUMA at the BIOS level can improve throughput for MySQL primary servers. This improvement is due to the more favorable memory allocation configuration provided by this setup for MySQL primary and similar applications.
4.4.6 System Call
Traditionally, the performance cost of system calls is primarily due to mode switch time. This time includes executing the system call instruction in user mode, transitioning to kernel mode, and eventually returning to user mode. Modern processors handle this mode switch as a processor exception, which involves flushing the user-mode pipeline, saving registers to the kernel stack, changing the protection domain, and directing execution to the exception handler. After this, a return from exception is needed to resume execution in user mode [17].
Frequent system calls can significantly impact MySQL’s performance. For example, Percona’s thread pool relies on system calls that introduce significant overhead, potentially reducing some of the performance gains from the thread pool.