The-Art-of-Problem-Solving-in-Software-Engineering_How-to-Make-MySQL-Better
4.11 Software Architecture Design
Common software architectures include layered architecture, primary-secondary/multi-primary architecture, and event-driven architecture. A standalone MySQL instance processing employs a layered architecture, while a cluster utilizes either primary-secondary or multi-primary architecture. At the lower level of communication, Paxos employs an event-driven architecture. Therefore, MySQL can be described as a hybrid of multiple architectural styles.
4.11.1 Layered Architecture
Layered architecture is a widely adopted architectural style that separates different concerns into layers to address varying requirements independently. For example, the TCP/IP protocol stack is one of the most successful layered architectures, widely used in the Internet domain. MySQL itself is based on a layered architecture, enabling it to support various types of storage engines. The processing model of Group Replication similarly follows a layered architecture, as depicted in the diagram [13].
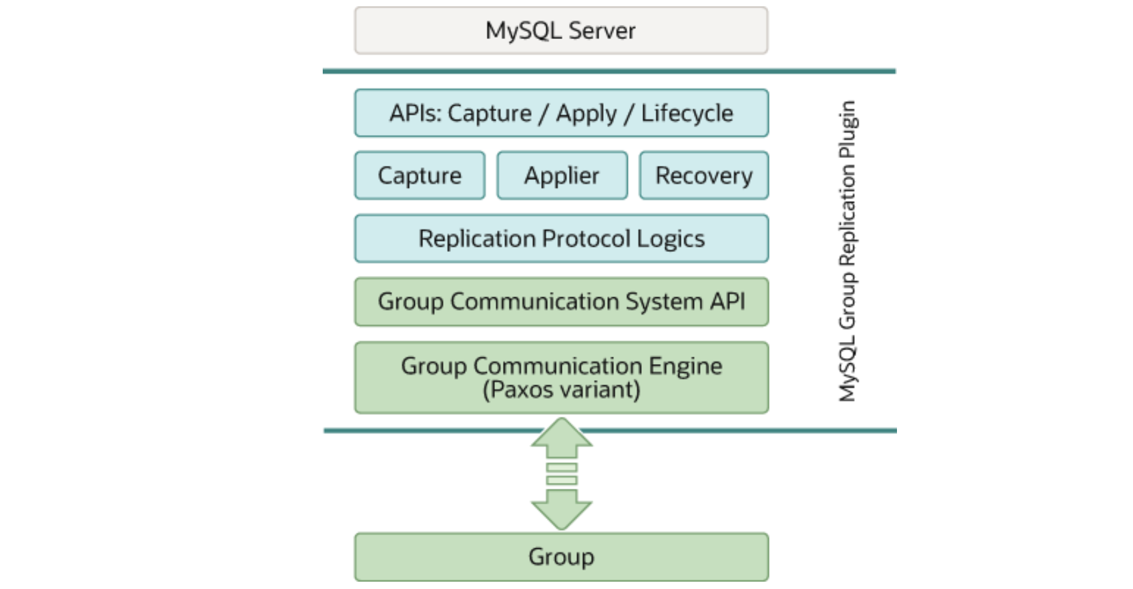
Figure 4-69. Group Replication plugin block diagram.
MySQL Server interacts with the Group Replication plugin through API calls. When a transaction needs to go through the Group Replication process, MySQL Server sends the transaction information to a designated queue via the Group Communication System API. Subsequently, the user thread enters a wait state, waiting for activation by threads responsible for Group Replication. The underlying Paxos layer (referred to as the Group Communication Engine in the diagram) is responsible for broadcasting the queue contents to group members. Once consensus is reached through the Paxos protocol, the upper layers are notified to proceed with further processing.
How is the scalability of this architecture? The following figure illustrates the relationship between Group Replication throughput and concurrency. Additionally, transaction throttling mechanisms are utilized to improve the scalability of InnoDB under scenarios with 2000+ concurrency, ensuring that too many user threads do not enter the InnoDB transaction system.
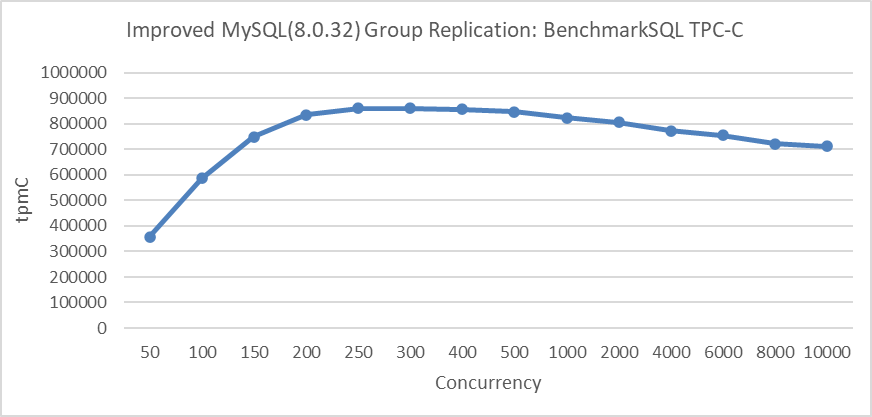
Figure 4-70. Group Replication TPC-C throughput in BenchmarkSQL with transaction throttling mechanisms.
From the figure, it can be seen that the architecture of Group Replication exhibits good inherent scalability, as the throughput does not sharply decrease with an increase in the number of threads.
4.11.2 Primary-Secondary/Multi-Primary Architecture
MySQL asynchronous replication, semisynchronous replication, and Group Replication single-primary all employ primary-secondary architectures. In MySQL, the primary executes transactions while the secondary replays them, and there is no need for synchronous coordination of writes between the primary and the secondary.
In a Group Replication multi-primary architecture, although transactions can be executed on any node, there are several known shortcomings:
- Lack of a global transaction manager.
- Limited transaction isolation levels.
- Potential for traffic skew under heavy write pressure.
According to user feedback, users often utilize Group Replication multi-primary in the following ways:
- They require that transactions between nodes do not conflict with each other.
- Despite being multi-primary, transactions are executed on only one node to avoid the overhead of switching primaries.
The following figure shows SysBench’s read-write performance over time, where each node accesses the same database and handles both read and write tasks.
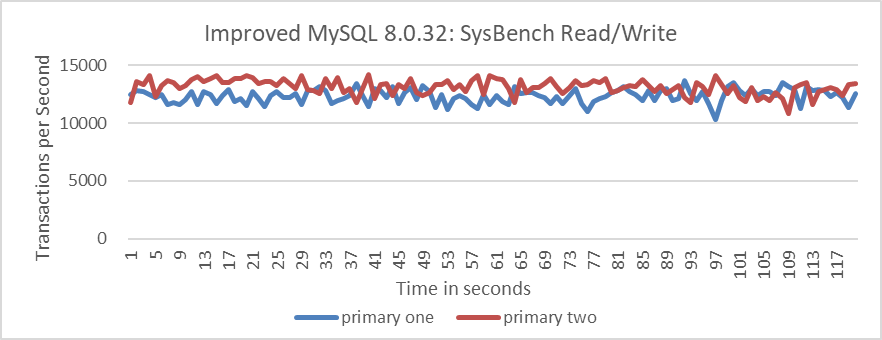
Figure 4-71. Group Replication throughput in SysBench read-write tests over time.
From the figure, it can be seen that the read-write tests between nodes coexist relatively harmoniously. The following figure shows SysBench write-only tests over time, where the Group Replication multi-primary architecture exhibits unstable throughput.
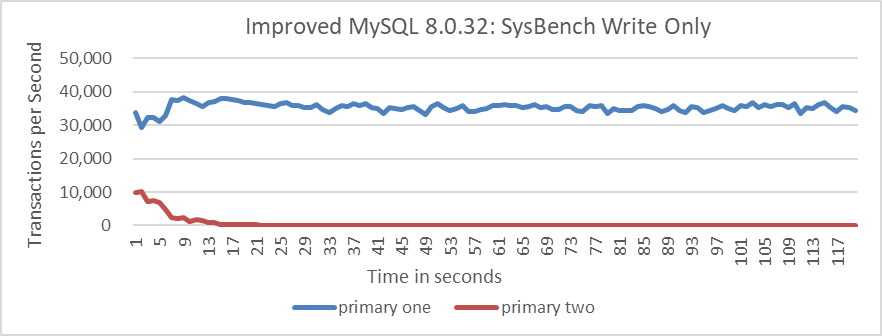
Figure 4-72. Group Replication throughput in SysBench write only tests over time.
Next, let’s continue to examine the testing scenario in the Group Replication multi-primary architecture, where transactions between nodes do not conflict. Testing is conducted on primary one for Database one and on primary two for Database two. This setup ensures that transactions executed by primary one and primary two have no possibility of conflict. The specific results are shown in the following figure:
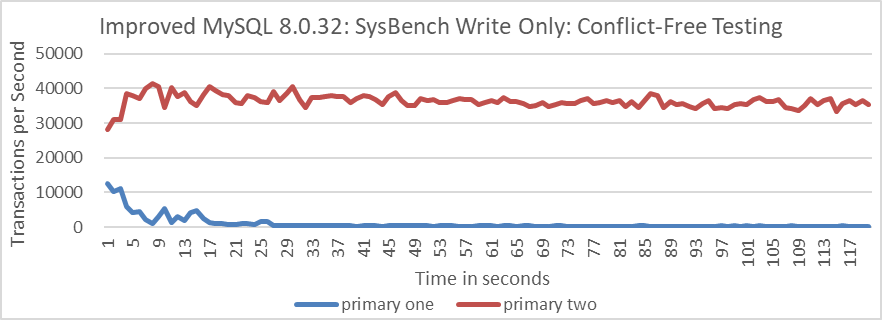
Figure 4-73. Group Replication throughput in SysBench write only tests: high concurrency and no conflicts over time.
From the figure, it can be seen that even without conflicts between transactions on different nodes, there is still throughput skew. The “primary one” node is primarily replaying transactions, severely limiting its capacity to accept new transactions.
Notably, these tests were conducted with 100 concurrency. Reducing the pressure to 10 concurrency alleviates the uneven traffic skew, as shown in the figure below.
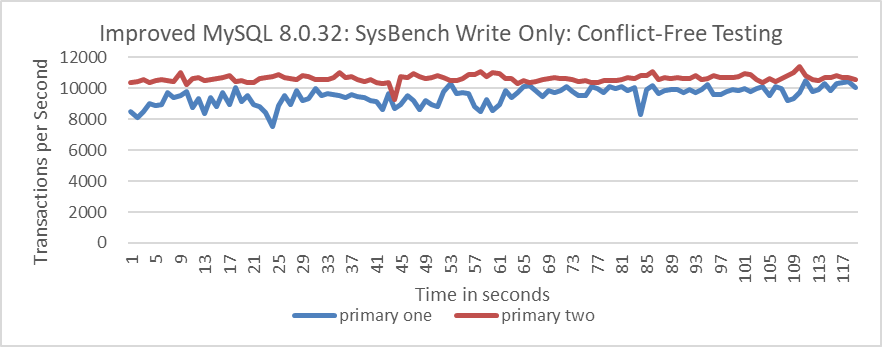
Figure 4-74. Group Replication throughput in SysBench write only tests: low concurrency and no conflicts over time.
The tests indicate that the scalability of the Group Replication multi-primary architecture is problematic and can only support small-scale traffic.
4.11.3 Event-Driven Architecture
Based on event-driven architecture, common in web servers like Nginx, Percona’s thread pool can be seen as a rough approximation of event-driven systems. However, event-driven architecture isn’t free—it incurs overhead from system calls, and this additional overhead constitutes the cost of using a thread pool.
MySQL’s underlying Paxos communication can also be viewed as asynchronous event-driven. This communication operates in a single-threaded mode, requiring the avoidance of any synchronous communication processes. Unfortunately, MySQL has gradually violated these principles in its ongoing feature expansion, leading to throughput problems in certain scenarios due to prolonged synchronous processes dropping to zero. For problems related to Group Replication synchronization, refer to the highlighted code snippet below.
/* Try to connect to another node */
static int dial(server *s) {
DECL_ENV
int dummy;
ENV_INIT
END_ENV_INIT
END_ENV;
TASK_BEGIN
IFDBG(D_BUG, FN; STRLIT(" dial "); NPUT(get_nodeno(get_site_def()), u);
STRLIT(s->srv); NDBG(s->port, u));
// Delete old connection
reset_connection(s->con);
X_FREE(s->con);
s->con = nullptr;
s->con = open_new_connection(s->srv, s->port, 1000); // synchronous call
if (!s->con) {
s->con = new_connection(-1, nullptr);
}