The-Art-of-Problem-Solving-in-Software-Engineering_How-to-Make-MySQL-Better
4.1 System Architecture
System architecture defines the high-level structure of a software or hardware system, detailing its components, their interrelationships, and how they collaborate to fulfill system objectives.
4.1.1 SMP
In an SMP (Symmetric Multiprocessing) system, multiple tightly-coupled processors share all resources such as bus, memory, and I/O system. This architecture facilitates equal access to memory, peripherals, and the operating system across all CPUs without distinction, emphasizing shared resource utilization among processors.
The following is a typical SMP architecture diagram.
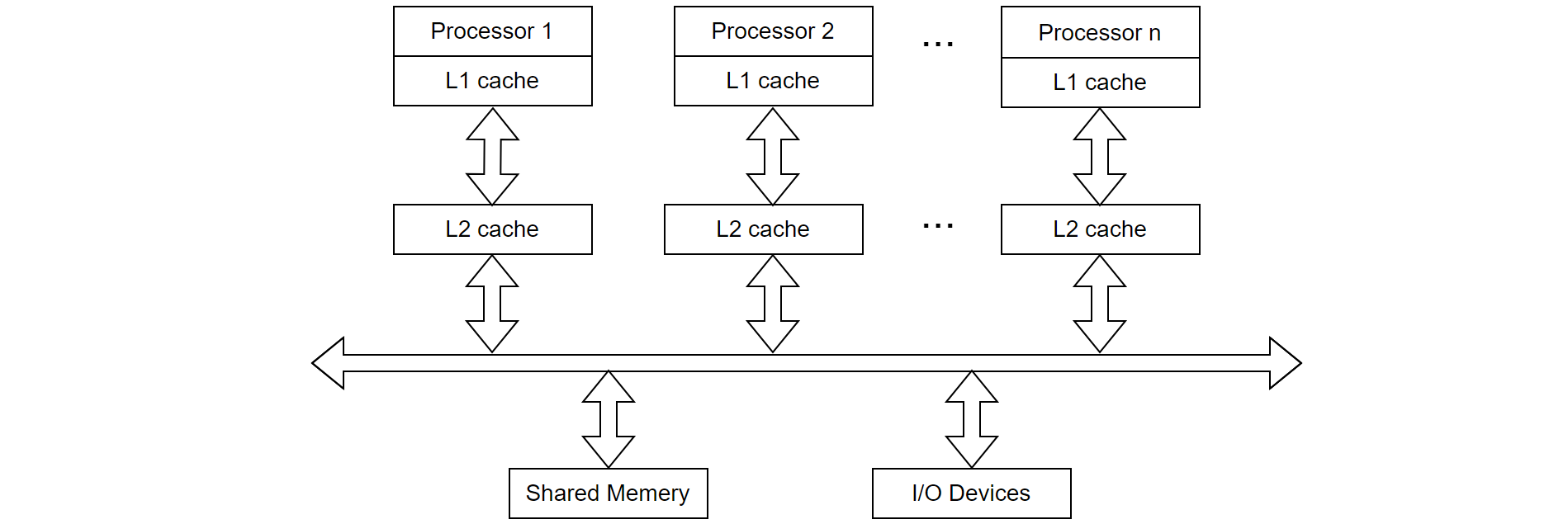
Figure 4-1. A typical SMP architecture.
In this setup, access to local L1 and L2 caches is extremely fast, and the overhead of CPU switching is minimal compared to NUMA architecture. SMP architecture typically supports moderate throughput under normal conditions. However, it is the inability of SMP to scale effectively for higher throughput demands that led to the development of NUMA architecture.
4.1.2 NUMA
In the era of increasingly multicore systems, memory hierarchy is evolving towards non-uniform distributed architectures. Non-uniform memory architecture (NUMA) systems, which offer superior scalability compared to SMP counterparts, feature multiple memory nodes distributed throughout the system. Each node is physically adjacent to a subset of cores, but the entire physical address space of all nodes is globally visible, allowing cores to access memory locally or remotely. Consequently, data access times are non-uniform and vary based on data location. Accessing data from a remote node can lead to performance degradation due to latency and interconnect contention if many cores access large amounts of data remotely. These problems can be mitigated by co-locating threads with their data whenever possible, facilitated by NUMA-aware scheduling algorithms.
The throughput of the cross-chip interconnect is typically lower than that of on-chip memory controllers. Remote memory accesses that traverse this interconnect also experience higher latencies compared to local memory accesses. Due to the diversity in their memory interfaces, these multiprocessors are categorized as NUMA systems. The performance impact of remote memory accesses can be significant; in current implementations, the NUMA factor can result in up to a 2X slowdown for certain applications.
NUMA nodes are interconnected within the same physical server. When a CPU needs to access remote memory, it incurs a wait time. This limitation is fundamental to why NUMA servers struggle to achieve linear performance scalability as CPUs increase [52].
Here is the classic architecture figure of NUMA.
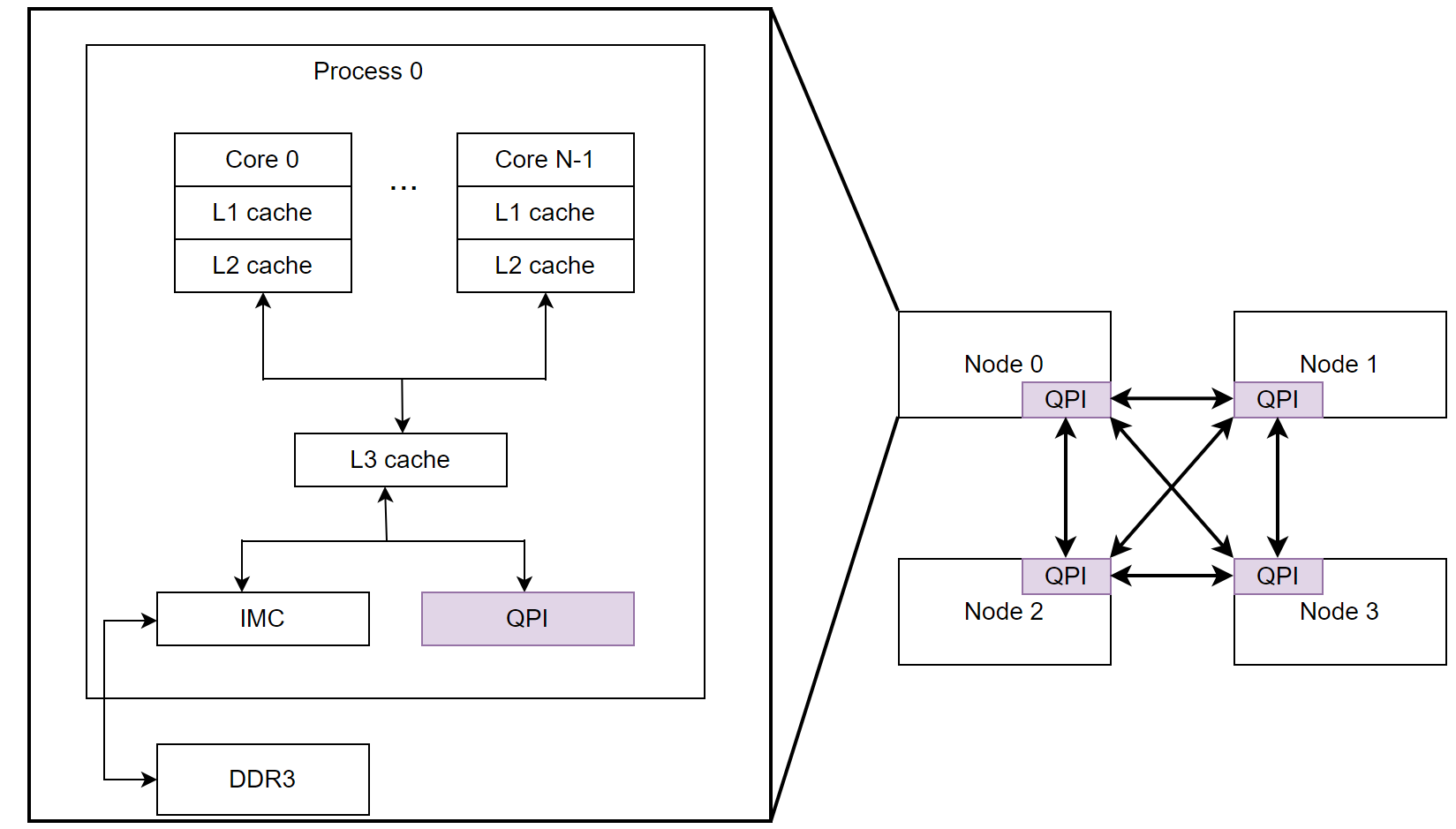
Figure 4-2. A typical NUMA architecture.
Access within the same NUMA node can be compared to a specialized form of SMP access, where its efficiency primarily comes from reduced CPU switching costs within the NUMA node. However, a drawback is that memory bandwidth within the same NUMA node can quickly become a bottleneck, constraining scalability. Accessing memory between different NUMA nodes involves higher costs, but it offers greater overall memory bandwidth. Effectively managing memory access in a NUMA environment poses a significant challenge.
The figure below illustrates the comparison results of TPC-C tests across different concurrency levels. The dark blue curve shows tests conducted with NUMA node 0 fixed, while the deep red curve represents tests utilizing all 4 NUMA nodes of the machine. The testing employed an improved version of MySQL, operating with 1000 warehouses and using the widely adopted Read Committed transaction isolation level.
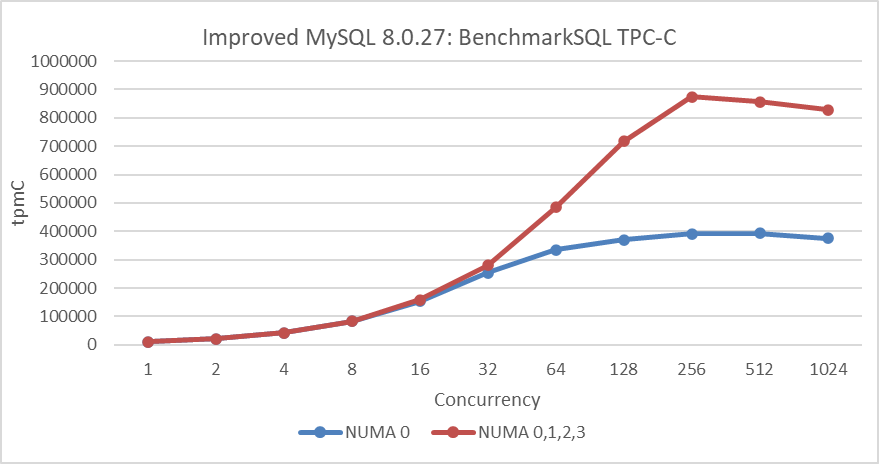
Figure 4-3. Performance Comparison in SMP vs. NUMA.
In the scenario where NUMA node 0 is bound, the throughput versus concurrency curve is notably smooth. Even under high concurrency, there is only a slight decline in throughput, indicating low thread context switching costs. However, throughput consistently remains below 400,000 tpmC due to significant limitations in memory bandwidth, characteristic of traditional SMP architecture.
In contrast, when utilizing all NUMA nodes, the throughput curve is relatively worse. This is attributed to reduced memory efficiency and increased context switching costs when accessing across NUMA nodes, resulting in less stable throughput. Nevertheless, scalability is greatly improved, with peak throughput increasing by 123% compared to using a single NUMA node.
Using 4 NUMA nodes does not result in four times the throughput; instead, it is approximately 2.x times that of a single NUMA node. This non-linear scaling is inherent to NUMA architecture and is compounded by MySQL’s challenges in linear scalability.
MySQL’s difficulties in achieving linear scalability arise from several factors, including the Read Committed transaction isolation mechanism based on MVCC ReadView. This involves copying a global ReadView to a local one, leading to contention among threads for global ReadView updates. Moreover, in NUMA environments, frequent cross-NUMA node accesses are necessary, further complicating scalability.
Many pieces of code are not suitable for NUMA environments. For example, frequent latch contention in critical sections can lead to frequent cross-NUMA node context switches. Slow operations within critical sections can cause inefficient program execution due to frequent cache migrations across NUMA nodes.
To achieve optimal performance on NUMA systems [4], the following strategies are crucial:
- Maximize the proportion of memory accesses routed to local nodes.
- Balance traffic across nodes and interconnect links.
An unbalanced distribution of memory requests can significantly increase memory access latency on overloaded controllers, sometimes reaching up to 1000 cycles compared to approximately 200 cycles on non-overloaded controllers.
While Microsoft SQL Server and Oracle DBMS are NUMA-aware, MySQL is not [5]. Therefore, large-scale applications like MySQL, which lack NUMA awareness, offer significant optimization potential in NUMA environments.
Interestingly, for MySQL, disabling NUMA can potentially improve performance. According to a case study in Section 2.9, disabling NUMA configuration in the BIOS improved performance for the MySQL primary. This adjustment impacts memory allocation strategies, leading to more consistent memory access between NUMA nodes. This aligns with optimization strategy 2 mentioned above, benefiting MySQL’s throughput and stability.
4.1.3 X86 Architecture
X86 uses a complex system called CISC (Complex Instruction Set Computing). This can do a lot of tasks at once but makes the processor more complicated and expensive to create. X86 architectures allow more direct interaction with memory, facilitating a depth of computational tasks at the expense of higher power consumption [45]. Overall, x86 has higher performance capabilities, ideal for demanding computational tasks.
For mainstream NUMA machines utilizing the x86 architecture, please refer to the figure below for an analysis of memory access overhead between different NUMA nodes on a specific machine:

Figure 4-4. Node distances in a typical x86 architecture.
From the figure, it is evident that under the x86 architecture, the access overhead is 10 units for accessing the local node and 21 units for accessing remote NUMA nodes. Below are the TPC-C test results of improved MySQL 8.0.27 with BenchmarkSQL:
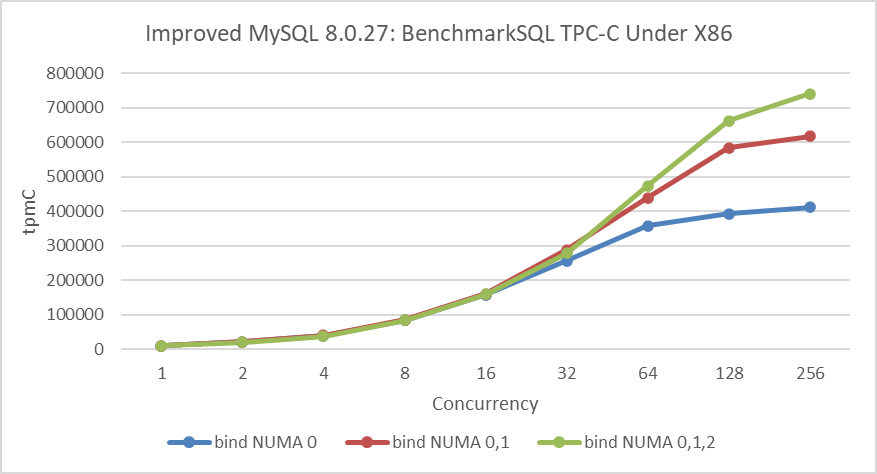
Figure 4-5. Performance comparison under different NUMA bindings in a typical x86 architecture.
Under the x86 architecture, the addition of each NUMA node results in a noticeable increase in high-concurrency throughput. This highlights the robust performance capabilities of x86 architecture in effectively managing memory access across NUMA nodes, thereby leveraging its full potential for high-performance computing.
4.1.4 ARM Architecture
Historically, ARM processors have prioritized power efficiency, dominating the mobile systems market, whereas x86 processors have led in high-performance computing. The primary distinction between ARM and x86 processors lies in their instruction sets: ARM utilizes the RISC (Reduced Instruction Set Computing) architecture, which simplifies instructions to enhance speed and energy efficiency. This simplicity makes ARM ideal for battery-powered devices like smartphones [47]. In contrast, x86 employs the CISC (Complex Instruction Set Computing) architecture, which supports a wider range of complex operations but typically consumes more power.
Regarding memory handling, ARM processors focus on register-based processing to minimize direct memory access, thereby improving energy efficiency. In contrast, x86 architectures allow for more direct interaction with memory, enabling a broader range of computational tasks at the cost of higher power consumption. Servers based on ARM architecture are renowned for their low power consumption and cost-effectiveness. However, they generally exhibit lower overall performance compared to x86 architecture and may have limitations in memory access scalability.
For mainstream NUMA machines utilizing the ARM architecture, please refer to the figure below to observe the memory access overhead between different NUMA nodes on a specific machine:

Figure 4-6. Node distances in a typical ARM architecture.
The memory access overhead between different NUMA nodes under the ARM architecture is notably more complex and varies significantly compared to the x86 architecture.
Here are the test results on an ARM machine, using MySQL code and configuration similar to those on an x86 machine, with approximately the same settings, including 1000 warehouses.
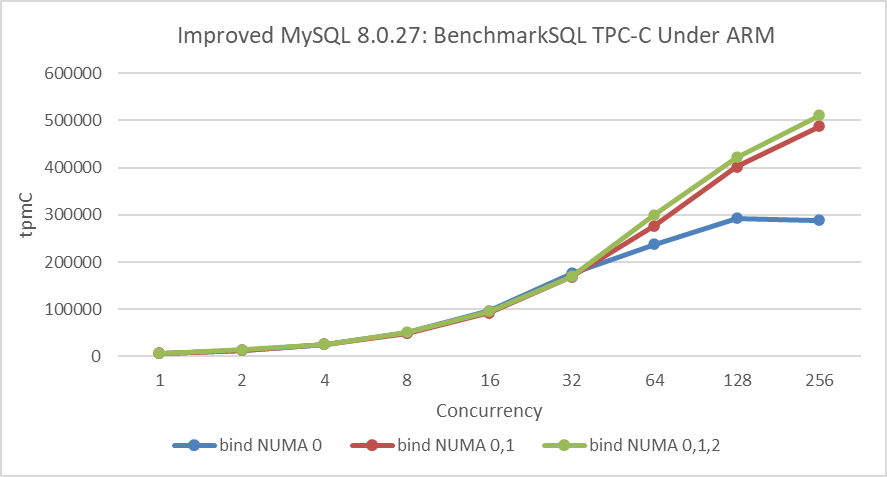
Figure 4-7. Performance comparison under different NUMA bindings in a typical ARM architecture.
From the figure, it is evident that binding NUMA node 0 and 1 significantly improves throughput. However, adding NUMA node 2 does not noticeably improve throughput, primarily due to NUMA node distances inherent in the ARM architecture. Extensive testing has revealed that MySQL demonstrates better scalability on x86 architecture compared to ARM.